Note: The 2025 batch represents genuinely novel knowledge that post-dates model training, while the 2021 batch may overlap with pretraining data. The dramatic performance differences highlight the challenge of dynamic knowledge evaluation.
Retrieval shows dramatically higher relative improvements on novel 2025 knowledge
Performance typically declines from L1 to L3, reflecting greater sensitivity to retrieval precision
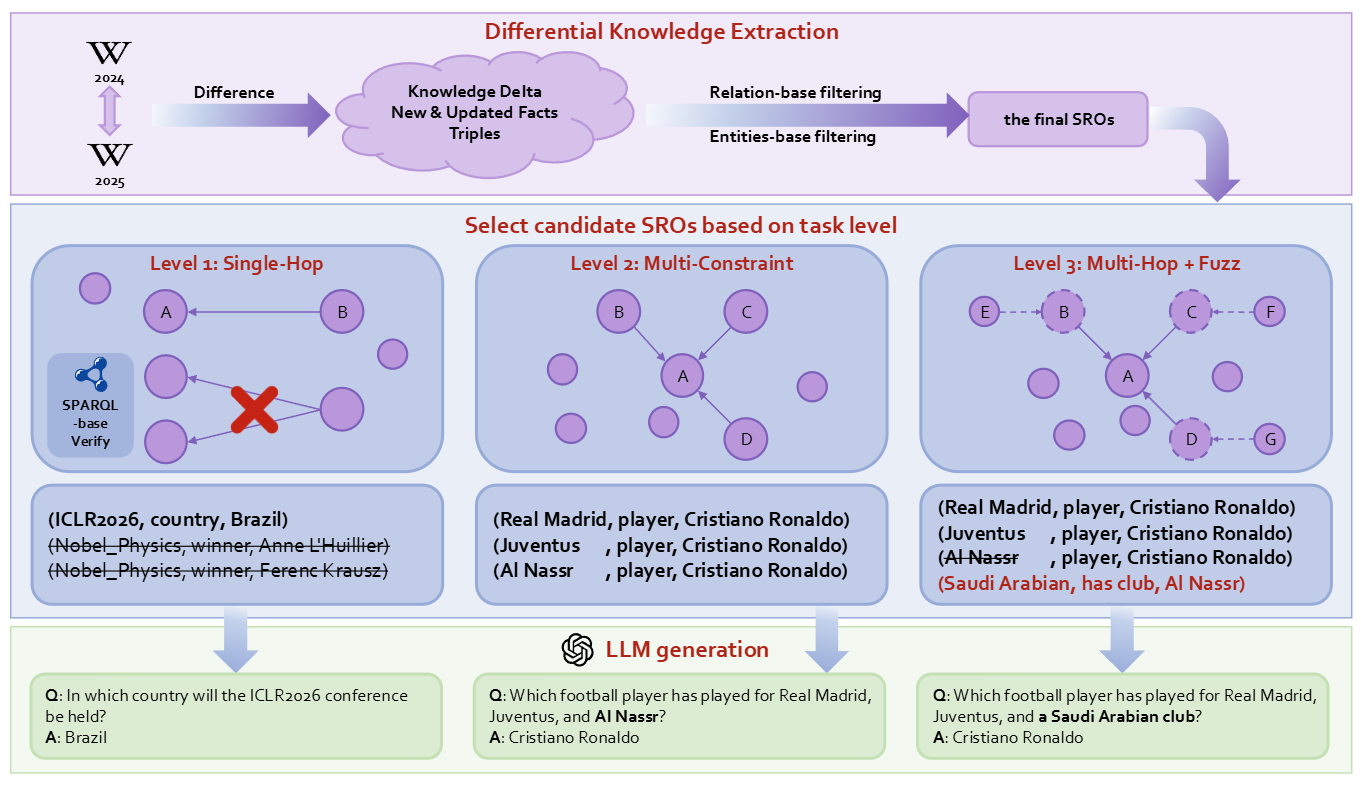
Compute deltas between successive Wikidata snapshots (T₀ → T₁) to identify new & updated facts
Apply relation allow-lists, entity quality checks, and statement validity filters
Generate L1 (single-hop), L2 (multi-constraint), L3 (multi-hop+fuzz) questions
SPARQL validation ensures each question admits exactly one verifiable answer
Q: "In which country will the ICLR2026 conference be held?"
A: Brazil
Based on triple: (ICLR2026, country, Brazil)
Q: "Which football player has played for Real Madrid, Juventus, and Al Nassr?"
A: Cristiano Ronaldo
Requires intersection of multiple constraints, based on (Real Madrid, player, Cristiano Ronaldo), (Juventus , player, Cristiano Ronaldo), (Al Nassr , player, Cristiano Ronaldo)
Q: "Which football player has played for Real Madrid, Juventus, and a Saudi Arabian club?"
A: Cristiano Ronaldo
Fuzzes "Al Nassr" → "Saudi Arabian club" + additional reasoning hop
Automated pipeline that continuously harvests questions from real-world editing streams with temporal correctness validation
Extensive evaluation of state-of-the-art LLMs and RAG methods revealing strengths and limitations in dynamic knowledge handling
Continually updating benchmark enabling the community to track progress on retrieval-augmented methods under realistic conditions
Our experiments demonstrate that current LLMs face significant challenges when confronting knowledge that post-dates their training. The performance gap is most pronounced on multi-hop reasoning tasks, where models must integrate multiple pieces of recent information. This finding highlights the critical need for benchmarks that reflect the dynamic nature of real-world knowledge and adequately test models' ability to retrieve and reason over up-to-date information.
| Rank | Model | Level 1↕ | Level 2↕ | Level 3↕ | Average↓ |
|---|
| Rank | Model | Level 1↕ | Level 2↕ | Level 3↕ | Average↓ |
|---|
@misc{zhou2025livesearchbenchautomaticallyconstructedbenchmark,
title={LiveSearchBench: An Automatically Constructed Benchmark for Retrieval and Reasoning over Dynamic Knowledge},
author={Heng Zhou and Ao Yu and Yuchen Fan and Jianing Shi and Li Kang and Hejia Geng and Yongting Zhang and Yutao Fan and Yuhao Wu and Tiancheng He and Yiran Qin and Lei Bai and Zhenfei Yin},
year={2025},
eprint={2511.01409},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2511.01409},
}